Article
Stop Chasing Broken Brackets: The JSON Repair Workflow For Reliable LLM Outputs In 2026
Learn a practical five-step JSON repair workflow that helps teams turn inconsistent LLM output into reliable, parseable JSON in production.

- #json repair
- #llm structured output
- #json validation
- #schema validation
- #ai reliability
- #prompt engineering
- #jsonberry
LLMs still break JSON more often than most teams admit, and StructuredRAG reports an average JSON-response success rate of only 82.55% across six tasks, which is not good enough when your CI or production pipeline expects 100% parseable data.
Key Takeaways
Question | Short Answer |
|---|---|
1. What is a "JSON repair" workflow for LLMs? | A deterministic pipeline that catches invalid or partial JSON from LLMs, repairs it, validates it, and returns a guaranteed parseable object, usually without a second API call. |
2. Why use JSON instead of XML for LLM outputs in 2026? | SoEval reports 88% valid JSON vs 72% XML for large models, which means JSON gives you a better baseline before repair logic does the rest. |
3. How do I quickly inspect and repair JSON locally? | Use our in-browser converter at jsonberry.com/#convert, which keeps all JSON processing on your machine with no uploads or accounts. |
4. Do I need JSON Schema for a repair workflow? | You do not, but schema-aware validation and repair give you stronger guarantees and are increasingly common now that major platforms expose JSON schema response formats. |
5. Can JSON repair actually improve extraction accuracy? | Yes, PromptPort shows +6 to +8 F1 from format repair alone, and even higher gains when combined with verification and canonicalization layers. |
6. How much overhead do structured outputs add? | Typical JSON-format prompts cost around +10 to +20 tokens, with full structured patterns adding up to +50 to +200 tokens depending on schema complexity. |
7. Where does in-browser tooling like Jsonberry fit? | We fit in at the human-in-the-loop and debugging layers, giving you instant validation and format conversion without leaking data off your laptop. |
Why JSON Repair Matters For LLM Workflows In 2026
JSON has become the de facto output format for production LLM workflows in 2026, but it still fails often enough that you cannot just "parse and pray".
When StructuredRAG measures only 82.55% JSON-response success on average, you need a systematic workflow that upgrades that probabilistic behavior into deterministic guarantees.
Structured outputs are "usually correct", which is not enough
Benchmarks like SoEval show JSON is structurally valid far more often than XML, but your systems do not care about "often", they care about "always".
Every invalid object is an incident, a broken job, or an alert that should never have fired in the first place.
Repair is cheaper than retries
Two-stage repair patterns, like the CigaR work for program repair, reduce token costs by up to 73%, which maps directly to JSON repair when you avoid full re-generation calls.
Local repair of brackets, commas, and types is usually a few microseconds of CPU instead of another network round trip plus model latency.
Where Jsonberry fits into the picture
We build tooling for developers who already speak JSON, TOML, and schemas, and who need fast feedback instead of pretty dashboards.
Our homepage and utilities are 100% client side so when you drop LLM output into a panel, you can verify behavior without leaking production data anywhere.
Core Concept: What We Mean By A "JSON Repair" Workflow
A JSON repair workflow is a tight loop around your LLM that takes potentially malformed JSON text and outputs a guaranteed valid JSON object, every time.
We keep this loop simple so you can reason about it and debug it under pressure.
The 5 essential stages
1. Constrained prompting to bias the model toward strict JSON.
2. Raw capture of whatever the model produced, including partial fragments.
3. Best-effort repair that fixes structural issues without changing semantics.
4. Validation against optional JSON Schema or light structural checks.
5. Fallback logic when repair fails, like re-asking or returning a safe default.
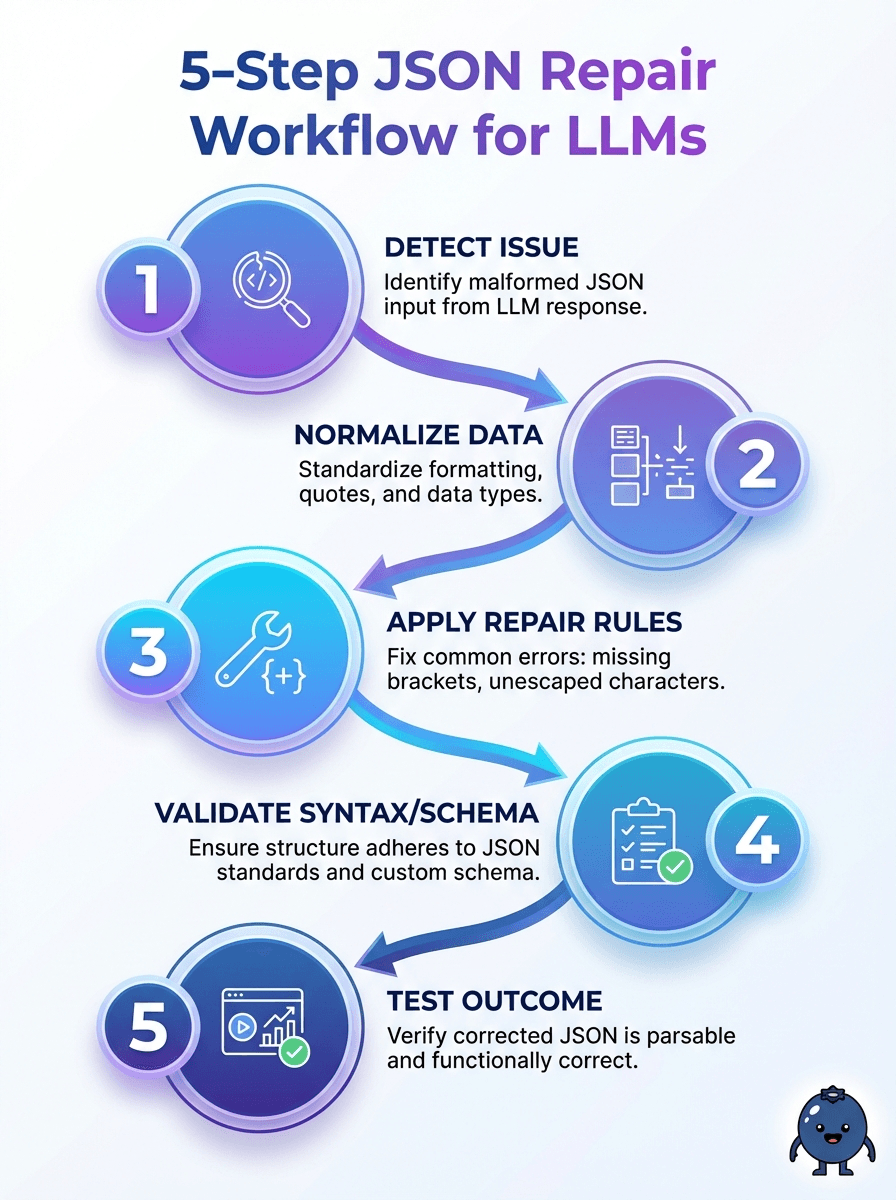
In practice, you might implement two or three layers of repair, starting with cheap string fixes and escalating to parser-based approaches only when needed.
Each layer should be pure and deterministic so that bugs are reproducible and testable.
Determinism is the goal, not perfection
Per-field accuracy is a separate concern from structural validity, although they interact tightly in real systems.
PromptPort demonstrates per-field F1 near oracle levels, around 0.890 in zero-shot mode, when you combine canonicalization and verification on top of a stable repair pipeline.
Step 1: Design Prompts For JSON That Is Easy To Repair
If you want cheap repair later, you need predictable failure modes, and that starts with your prompts.
LLMStructBench in 2026 benchmarks 22 models and shows that prompting styles often matter more than pure model size for structured extraction tasks.
Keep the format contract brutally clear
We recommend instructing the model to output "only JSON, no prose" and to avoid trailing comments or explanations around the object.
Simple examples in your prompt help, like a tiny valid JSON snippet with the same shape you expect from the model.
Prefer JSON over other formats for structured outputs
SoEval highlights a 16 percentage point advantage for JSON over XML in structural compliance for large models, 88% versus 72%, which makes JSON the obvious choice when you actually need things to parse.
That gap means less repair work, less custom logic, and fewer tail failures in long running jobs.
Limit optionality in the shape
When your schema has "maybe fields" everywhere, repairing becomes guesswork because you cannot distinguish "missing" from "truncated".
A narrow, explicit schema is easier to repair, easier to validate, and easier to explain to the rest of your team.
Step 2: Capture And Isolate The Raw LLM Output
Before we talk about fixing anything, we need the raw text exactly as the model produced it, with no middleware "helpfulness".
That means disabling auto-trimming, "smart" postprocessors, or ad hoc regex hacks that mutate the payload in place.
Log everything around the JSON
We recommend logging at least the prompt, the model name, the temperature, and the raw output so you can correlate repair failures with upstream changes.
StructEval shows that generation tasks across formats still have a lot of variance, so you will want that transparency when you swap models or tweak settings.
Treat JSON as untrusted input, even from your own model
Your repair code should expect arbitrary bytes, partial Unicode, or misaligned braces without crashing or hanging.
Think of it like user input on a public API, even though the "user" is your LLM instead of a browser.
Keep local inspection tools nearby
During debugging, high friction kills insight, which is why we provide a keyboard friendly panel at jsonberry.com/#convert for fast copy and paste workflows.
Because everything runs in your browser with no uploads, you can throw real production-shaped JSON at it without waiting for approvals.
Did You Know?
PromptPort findings show severe format collapse across model families, with strict parsing scores as low as 0.116 compared to 0.246 after canonicalization on a 0–1 scale, which underlines how much reliability you gain by adding a repair layer.
Step 3: Implement Lightweight Syntactic JSON Repair
Your first repair pass should handle trivial syntax issues cheaply, things like missing commas, trailing commas, or stray text before or after the JSON object.
This layer is typically language specific glue using your standard JSON parser, not a second LLM call.
Common failure modes to target first
Objects that start or end mid structure, such as missing the final closing brace.
Trailing commas in arrays or objects that strict parsers reject.
Double encoded JSON, like a JSON string containing another JSON string.
Extra prose, such as "Here is your result" followed by the JSON.
You can often fix these with deterministic substring operations, targeted regexes, or by scanning for the first balanced JSON object in the text.
Once you have a candidate slice, run it through a strict parser and catch exceptions as signals for the next layer of repair.
Token overhead and cost awareness
Structured output patterns usually add between +50 and +200 tokens on average, especially when you include instructions and example schemas.
That sounds expensive until you compare it with repeated full re-generations of broken outputs, which cost far more in both time and tokens.
Keep repair code transparent and testable
Your syntactic repair functions should be small, pure, and fully covered by unit tests that simulate the known bad cases from your logs.
We recommend snapshot style tests for input and output pairs so regression reviews stay fast and concrete.
Step 4: Add Schema-Aware Validation And Repair
Once you can reliably parse JSON, the next step in the workflow is to validate it against some notion of "correct shape".
In 2026, that usually means a JSON Schema, a typed DTO in your language, or at least a set of field level expectations you can assert.
Why schema scale matters
SchemaBench compiles around 40,706 diverse JSON Schemas to stress test models and pipelines, which shows how wild real world schemas can get.
Your own schemas will likely be narrower, but they will still evolve over time as your use cases grow and change.
Soft repair vs hard failures
When validation fails, you can attempt soft repairs, such as defaulting missing optional fields, coercing strings into numbers, or trimming unrecognized properties.
Hard violations, such as wrong enum values or structurally impossible shapes, should short circuit the repair and trigger your fallback workflow instead of guessing.
Industry push toward schema based outputs
Major platforms started exposing JSON Schema response formats for models like GPT-4o in 2025 and that momentum has only accelerated in 2026.
That means your workflow can pull the same schema definitions into both your LLM calls and your server side validation so the contract stays single sourced.
Step 5: Verification, Canonicalization, And Confidence Scoring
The last repair pass is semantic, not just syntactic, and it is where you normalize fields, remove ambiguity, and compute confidence signals.
Canonically sorted keys, stable value formats, and normalized types all make diffing, caching, and downstream analytics much easier.
Canonically format JSON for stable diffs
PromptPort reports substantial gains from adding canonicalization and verification, with +6 to +8 F1 from format repair alone and an additional +14 to +16 F1 once verification logic is in place.
Sorting keys, normalizing boolean and null handling, and trimming whitespace do not just please your linter, they improve machine learning quality metrics.
Attach confidence to fields, not just objects
For critical systems, you want per field confidence, such as "this enum is safe to trust" versus "this free text probably needs human review".
That can come from soft signals like validation distances, model logprobs where exposed, or handcrafted heuristics tuned to your domain.
Log repair decisions aggressively
Every repair step should be logged or at least traceable, so if something goes wrong, you can replay and analyze the exact chain of events.
This is where a transparent, minimal workflow is easier to operate than an opaque stack of plugins.
Did You Know?
SoEval reports that large models output valid JSON about 88% of the time compared to only 72% for XML, which means choosing JSON as your structured format cuts your repair workload by a huge margin before you even add any workflow logic.
Fallback Strategies When JSON Repair Still Fails
No workflow is perfect, so you need clear rules for what happens when repair and validation still cannot produce a safe object.
Those rules should be explicit and boring, not improvised by whoever is on call that night.
Common fallback patterns
Retry with the same prompt if the failure looks transient.
Retry with a stricter prompt that removes optional fields or complexity.
Return a minimal safe object with a clear error field for downstream systems.
Route to human review for high risk or high value items.
Your JSON repair layer should surface a well structured error report, not just an exception stack trace, so the fallback logic can be deterministic.
In critical systems, you might decide that some endpoints should never retry automatically to avoid cascading effects.
Tie fallbacks into monitoring
Every repair failure is a signal that your prompts, models, or schemas might be drifting out of sync.
We recommend tracking failure rates over time so you can see if a model upgrade or new feature is quietly increasing your repair load.
Cost And Performance: Making JSON Repair Cheap Enough For Production
Repair is only useful if it stays cheap in both money and latency, especially in high volume pipelines.
The good news is that most of the heavy work can be deterministic and local, not delegated to more LLM calls.
Use LLM calls sparingly for repair
Work like CigaR shows that two stage repair with cost aware prompting can reduce repair token costs by 73%, which is a strong hint that more LLM is not always the answer.
We suggest keeping LLM based repair only for the rare cases where schema aware heuristics truly cannot recover the JSON.
Profile your workflow by stage
Measure how many objects fail at each layer, from syntactic parsing to schema validation to semantic checks, so you know where to invest engineering time.
If 95% of your issues are trailing commas, a more complex semantic repair agent is not going to move the needle.
Parallelize where possible
Deterministic repair and validation stages are easy to parallelize across workers or threads since they do not depend on external state.
That keeps end to end latency crisp even when individual objects need multiple repair attempts.
How Jsonberry Fits Into A JSON Repair Workflow
We are not your LLM, and we are not your production orchestrator, we are the quiet utilities that keep your structured data workflows clean and inspectable.
Jsonberry focuses on tight, client side tools that fit right into your repair and debugging loops without inserting another server into your stack.
In browser, zero upload JSON handling
Our converter at jsonberry.com/#convert does all parsing, formatting, and conversion in your browser, with no accounts, no ads, and no file uploads to any server.
You can paste in raw LLM output, fix structure, convert formats like JSON to TOML, and copy back out in seconds without leaking customer data.
Fast validation and visual diffing
The two pane editor layout keeps your original content and your repaired or converted version side by side so you can see exactly what changed.
Keyboard shortcuts keep the loop tight, which matters when you are stepping through tens or hundreds of edge case payloads during a debug session.
Designed for developers and CI pipelines
We write our copy and build our features for engineers who read specs, not for casual users who just want a pretty JSON viewer.
The same philosophies that make our tools predictable in the browser map cleanly to the deterministic repair logic you will write in your own services.
Putting It All Together: A Reference JSON Repair Pipeline For 2026
To close, it helps to see the full "JSON repair" workflow as a single, end to end path that you can adapt to your own stack.
This is the pattern we see working best in 2026 across production deployments that care about both reliability and cost.
Reference workflow overview
Prompt the model with strict JSON instructions and a minimal example.
Capture the raw text output verbatim and log context.
Repair syntax with deterministic string and parser based fixes.
Validate schema and attempt light semantic repairs where safe.
Canonicalize the final object and compute per field confidence where relevant.
Fallback with explicit retry and error handling logic.
Monitor repair and failure rates over time and feed them back into prompt and schema design.
Simple comparison of "naive" vs "repaired" approaches
Aspect | Naive JSON Output | JSON Repair Workflow |
|---|---|---|
Parseability | Fails on 10 to 20% of calls depending on task and model. | Targets 100% valid JSON objects. |
Error handling | Random parse exceptions in application code. | Centralized repair and explicit fallbacks. |
Cost profile | Multiple full re generations when things break. | Cheap deterministic fixes, rare second LLM calls. |
Observability | Scattered logs and inconsistent behavior. | Single repair layer with clear metrics. |
If you are still at the "parse and pray" stage, adopting even the first few steps of this pipeline will make your LLM driven systems calmer and easier to operate.
From there, you can iterate toward full schema aware, canonicalized workflows as your usage and risk profile grow.
Conclusion
In 2026, relying on LLMs to always emit perfect JSON is a luxury that production systems cannot afford, especially when benchmarks still show significant failure rates and format collapse without explicit repair layers.
A disciplined "JSON repair" workflow, anchored in strict prompting, deterministic syntactic fixes, schema aware validation, and clear fallbacks, turns that unreliable stream into something your CI and production jobs can trust.
Our role at Jsonberry is simple, we provide fast, private, in browser tooling so you can iterate on these workflows without friction, inspect real outputs safely, and keep your structured data pipelines crisp.
If your team is serious about LLMs in production, investing in a solid JSON repair workflow is not optional, it is table stakes for reliable automation this year and beyond.